





This blog post seeks to define and explain some common acronyms involved in today’s security management landscape.
What is UBA?
UBA stands for User Behavior Analytics and it’s an analytics led threat detection technology. UBA uses machine learning and data science to gain an understanding of how users (humans) within an environment typically behave, then to find risky, anomalous activity that deviates from their normal behavior and may be indicative of a threat.
How it works:
UBA seeks to understand normal behavior for all users in an environment and create a baseline for that behavior. How does that happen? It happens by using data science to build out a behavioral model for each attribute of a user interacting with an IT environment.
Let’s say we want to model out the VPN usage of the user Barbara. We could start to track various attributes of her VPN usage including things like the start and end times of her VPN sessions, the IP addresses she connects from, what country she logs in from, etc. For each of these attributes we can build a model by simply recording her usage and analyzing it with data science.
Let’s assume we’re building a model for what countries Barbara VPNs in from. Each time she connects we plot a data point.
Once we have enough data, data science can be used to identify trends in her VPN usage, and to understand what is normal activity for her. Conceptually speaking, this data could be used to create a chart like the following:
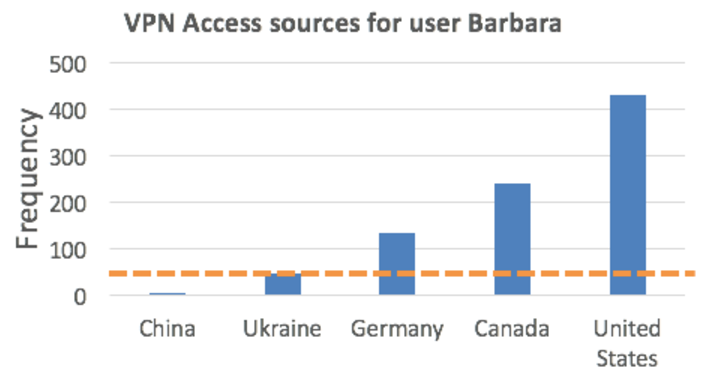
Once a baseline for normal activity has established, UBA can easily identify abnormal activity. Looking back at the chart above, the orange line is representative of her behavioral threshold; VPN’ing in from the US, Canada, or Germany would all be normal for Barbara, however anything below that threshold would be abnormal. In this example, Ukraine is right at the cut-off but its normal for her. Any VPN connections from a country which Barbara connects from less frequently than Ukraine would be anomalous, and would add risk points.
Risk Scores Reduce False Positives
Another core concept common to UBA solutions is the use of risk scores as opposed to individual security alerts. In UBA, a single abnormality is not enough for an incident to be escalated to analysts for review. Each behavioral abnormality discovered adds risk to the user. Once the user has enough points of risk within a specific period of time, that user is deemed to be notable or high risk. This approach reduces false positives because several abnormalities must occur before an analyst is alerted.
What is UEBA?
UEBA is exactly what it looks like: UBA with an E jammed in the middle of it. That E stands for Entities, making the new acronym User and Entity Behavior Analytics. What that really means is UEBA is able to model the behavior of both humans and also the machines within network. Taking a step back, every IT environment is an interconnected web of humans and machines, UEBA can identify normal and abnormal behavior for both groups to provide complete visibility.
Uncovering Machines Behaving Badly
This article would be vastly more interesting if my next point was about coffee machines and printers coming to life and doing nefarious things (a la Maximum Overdrive), but unfortunately that isn’t the type of machine behavioral anomalies we’re talking about. 
Instead, we’re actually talking things like the first time a machine runs an abnormal process, or a known process running from unusual location.
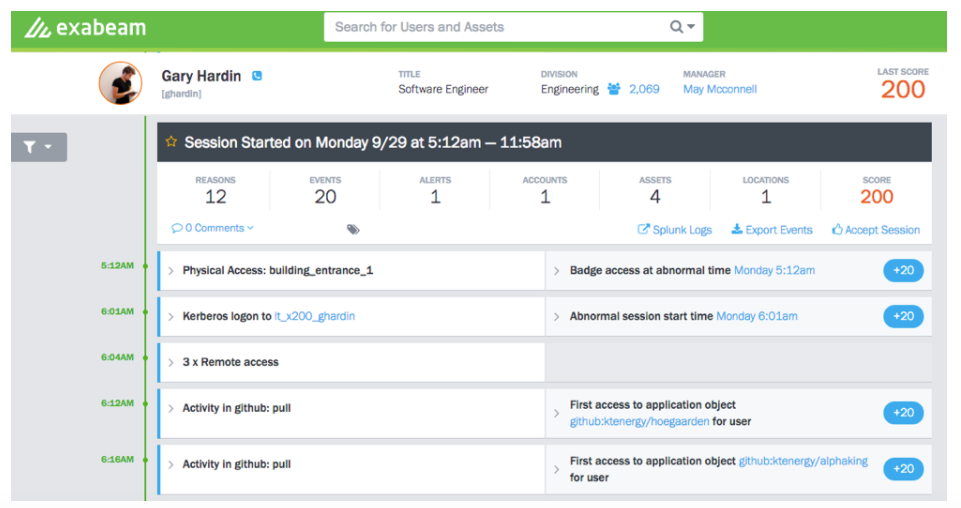
Let’s look at a real world example we discovered at a large US based tech company. The security incident they experienced involved a linux box which was compromised and being controlled by hackers. The hackers were essentially using this machine as a jump off point to search the rest of the network for vulnerable assets with the intent of furthering their compromise to those machines. The hackers scanned the network and its assets, then attempted to log into various servers using the default credentials of those servers.
In this example there were many behavioral abnormalities, but they were all associated with an entity: a specific IP address. Without the ability to track and model entity behavior, this attack would have gone unnoticed because the attack attempted to use many users (the default credentials) on various hosts. If behavioral analysis was only being performed at a user level, this attack would have appeared as several users on different systems failing to log in. The entity was what tied the attack together, and the ability to baseline and identify unusual machine behavior was what enabled us to quickly uncover the compromised machine before more damage could be inflicted.
What is a SIEM?
The acronym SIEM stands for Security Information and Event Management. SIEMs are the de-facto Security Management tools used by most enterprises. The original premise of SIEM was to help security teams collect and store event and log data, and correlate that data together to find threats. They are also used for compliance and reporting for companies which must adhere to compliance regulations like GDPR, PCI-DSS, and others.
The Components of SIEM
If we dissect the name, we can see that SIEM is an amalgamation of two other technologies: Security Information Management and Security Event Management.
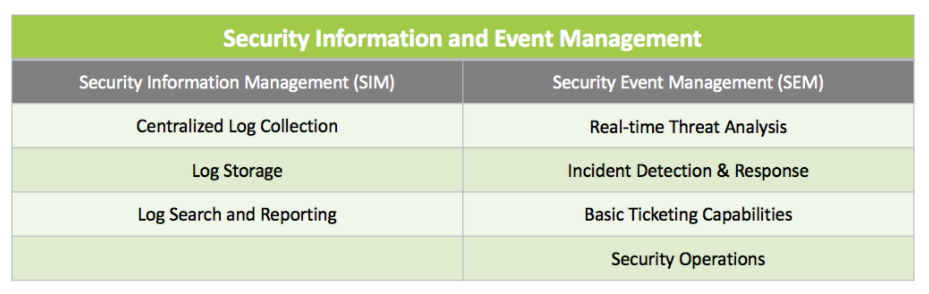
SIEMply put, Security Information Management (SIM) is all getting the data in one place and efficiently managing it. SIM includes the components which provide centralized log collection, log storage, log searching, and the reporting which enables compliance use cases.
Security Event Management (SEM) is the handful of features which enable threat detection and incident management use cases. It’s things like real-time analysis and using correlation rules for incident detection. SEM also includes response and operational features like case management which provides ticketing and security operations functionality.
Ye Ole Haystack Analogy

People often try to explain SIEMs using the “they help you find needles in the haystack” analogy. To be more accurate, if event logs were hay, SIEMs would be responsible for gathering that hay into the haystack (log collection and storage) and also for finding the needles in that haystack (real time threat detection, incident detection and response, etc.). While this is a great analogy for explaining a SIEM, it’s worth pointing out that legacy SIEMs do a much better job at gathering hay into an expensive hay stack than they do at finding needles in it.
Bonus: What is SOAR?
But wait! There’s more! Security management doesn’t stop with detecting threats. Security analysts and incident response teams still need to respond to the incidents they have discovered and that’s where SOAR comes in. Depending on who you ask, SOAR could stand for a myriad of things, but two of the most common definitions are:
- Security Operations, Analytics and Reporting (SOAR)
- Security Orchestration, and Automated Response (SOAR)
This category of solutions is also sometimes referred to as:
- Security Orchestration and Automation Platform (SOAP)
- Incident Response Automation
- Orchestration and Response Automation
No matter what it stands for, SOAR products are all about using automation to help reduce response times, improve consistency and amplify the productivity of incident response teams. Three of the key features which enable these IR productivity gains are:
- Incident Management – This feature can also be referred to as ticketing, or a case management. Incident management helps organize incident response efforts by assigning owners to incidents, tracking investigation statuses and priorities, and providing a centralized system for gathering and working through evidence.
- Security Orchestration – Orchestration tools typically use pre-built, bi-directional APIs to connect and coordinate various security and IT infrastructure solutions. These APIs make it easy to pull information from other systems, as well as run actions in those systems. For example, orchestration could be used to programmatically obtain IP reputation information or adjust a firewall rules.
- Response Play Books – Play books kick orchestration into high-gear. They logically string together many actions from different systems to achieve specific tasks like investigation, containment, or remediation.
For example, you might have a play book that performs the following actions in various systems with a single button click:
- Pulls in all emails received by a user at the time of their infection (e.g. from an email server)
- Parses the emails to extract URLs and attachments
- Detonates the attachments in a sandbox (e.g. Cisco Threatgrid or other)
- Obtains the URL reputations with a reputation service (e.g. Cisco Umbrella
- Geo-locates any network connections being made by the attachments in the Sandbox with a geolocation service (e.g. Maxmind)
- Uses machine learning to determine if any of the emails are phishing emails based on the info from steps 1 to 5 above
- Searches a SIEM/LMS for other users that have received the same emails. (e.g. Splunk or Exabeam Data Lake)
Further reading
- What UEBA Stands For (And a 5-Minute UEBA Primer)
- What is User Behavior Analytics (UBA/UEBA): The Key to Uncovering Insider and Unknown Security Threats
- What is Insider Threats: How to Stop the Most Common and Damaging Security Risk You Face
- Stop Destroying Evidence: Why Understanding the Entire Attack Chain Before Responding is Critical
Similar Posts

Augmenting Microsoft Sentinel SIEM: The Power of Exabeam for UEBA and TDIR

Exabeam Unveils 2023 Partner of the Year Award Winners

Exabeam IRAP Assessment Completion Creates New Opportunities for Partners in Australia
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!