




Demystifying the SOC, Part 4: The Old SOC Maturity Model based on Speeds and Feeds

Editor’s note: This post was first published on Medium.com.
So far in this series on the security operations center (SOC), we’ve discussed why you need a SOC, why threat prevention alone is not good enough, and why you already have a SOC, whether you know it or not.
The next topic: Do you have the right approach as you think about your SOC? Is your SOC operating under the right maturity model? You may think that the older SOC maturity model and older metrics based on speeds and feeds are still fine, but the truth is that this model based on such metrics as MTTD and MTTR are plain wrong. If your organization is like most today, you may be wasting precious security resources approaching the problem the wrong way.
The SOC as the evolution of the NOC
Most legacy SOCs are actually a spinoff of the network operations center (NOC). The NOC was a well understood machine, organized in three tiers. Tier 1 was the entry point in the NOC, and the hardest problems to solve were escalated all the way to tier 3. Most of the problems that the NOC would deal with could be solved using a known script with repeatable and discrete steps, along a well understood phased lifecycle. It was then natural to track and measure how long it took for the cases managed by the NOC to progress from one phase to the other, and to try to minimize that duration.
The NOC was also treating security issues, but these incidents were few and far between. Then, as these security problems became more and more prevalent, and more and more complex, organizations decided to create a NOC dedicated to security problems, i.e. the security operations center (SOC), modeled after the NOC.
Modeling the SOC after the NOC was the best we could do back then, but it gave us the following way to track maturity.
Tracking the Threat Detection, Investigation and Response Lifecycle as discrete phases
Most SOC managers and analysts are familiar with the following diagram that depicts the main phases in the TDIR lifecycle. Although represented sequentially, some of these phases can happen in parallel or out of sequence. For those Gartner clients, you will recognize this diagram is an evolution of a similar diagram that I published as Gartner research with my colleague Pete Shoard at “Successfully Align Your Threat Detection and Incident Response Requirements to Your Service Providers” (Gartner subscription required).

- Preparation and Collection. In this phase, the organization makes sure that all the required content is available, e.g. log, event and content collection, detection rules, response playbooks.
- Detection. In this phase, one or more of the detection engines trigger an alert.
- Triage and assignment. In this phase, the alert is enriched and the determination is made — is this a false positive, or a true positive? If a true positive, who will work on this incident?
- Initial response. In this phase, the initial response will take place so as to mitigate further damage from the incident, e.g. a host will be put in quarantine, a rogue process will be suspended, credentials or authorizations will be temporarily revoked for a user.
- Incident diagnostic and investigation. In this phase, the organization will try to understand the full scope of what happened (e.g. the blast radius for the attack) and determine the intent for this incident — the what and the why.
- Incident closure. Once root cause is understood, the organization brings the environment back to a normal, known good state, e.g. an insider threat is permanently fired, or a server broken beyond repair is re-imaged.
- Post Mortem & Root Cause Analysis and continuous improvement. In this phase, the organization draws bigger lessons from this episode with the goal of continuous improvement. For example, do we have a hole in our technology stack that we need to plug, do we need to make configuration changes in our firewall which require change control, do we have the right skillsets to address this situation, are we running the proper processes for efficient InfoSec. These improvements are iterative in nature.
With enough demand, I will write another blog post to dive deeper into the specifics of this diagram, for now I am using it to illustrate the older and wrong maturity models for SOCs, and in the next blog post the new and correct maturity model for SOCs.
Older SOC maturity model based on Speeds and Feeds
When looking at the SOC as a series of discrete steps within a lifecycle, the initial thought is to try and understand how efficient the SOC is in each of the main phases of this workflow. How long on average before I can detect an incident? How long on average before I can do the initial response to an incident, before I have answers to the root cause analysis, and ultimately how long before the incident is behind us and we are back to “normal”. This approach is what the older SOC maturity model is based on, and has yielded a maturity level from 1 to 4 based on what the SOC is capable of tracking and measuring consistently.
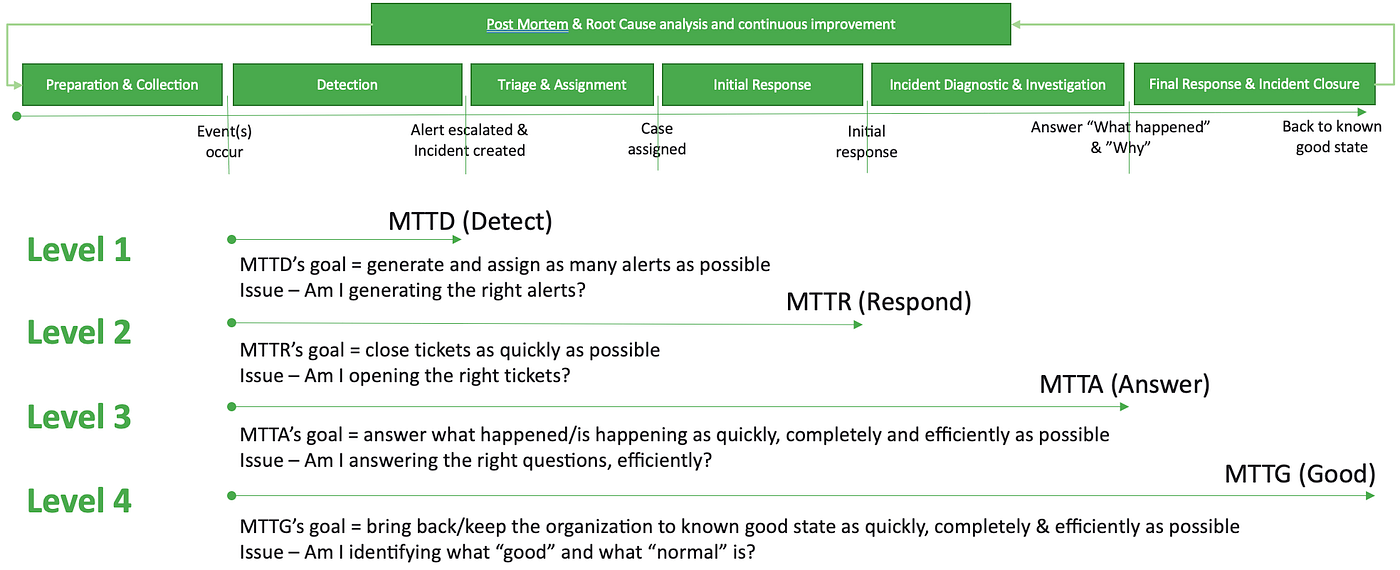
Level 1: Mean time to detect (MTTD). If all your SOC is tracking is MTTD, then it is likely that you have a level 1 maturity and only measure your SOC’s ability to detect the incidents that are hitting your organization. The lower the MTTD, the better your SOC can identify and detect incidents. Organizations focused on MTTD have typically generated too many alerts — they prefer to generate false positives rather than missing an incident.
Level 1 SOCs usually have threat detection tools capable of generating alerts such as IDPS, or EDR. Most also have a SIEM tool, and the more forward leaning level 1 SOCs have deployed a user and entity behavior analytics (UEBA) solution capable of improving the accuracy of these alerts.
Level 2: Mean time to respond (MTTR). If your SOC is only tracking MTTD and MTTR, it is likely that you have a level 2 maturity. You are now capable of measuring how long it takes your SOC to perform the initial response to the incidents that were validated and assigned.
Level 2 SOCs usually have more formalized playbooks for responding to incidents, and often have deployed some form of security orchestration, automation and response (SOAR) solution to automate some of these playbooks.
Level 3: Mean time to answer (MTTA). If your SOC is tracking MTTA (in addition to tracking MTTD and MTTR) then it is likely operating at a level 3 maturity level. The goal of tracking MTTA is to accelerate the investigation of incidents and the understanding of root cause, e.g. analysis of blast radius and attribution of intent.
Level 3 SOCs usually have great expertise in threat hunting, or leverage solutions that can accelerate this understanding by differentiating normal and abnormal behavior and presenting this understanding in timelines explaining the operational model of the attack and the attacker.
Level 4: Mean time to good (MTTG) This level often involves a lot of post breach analysis and labor to recover data and clean up and secure applications and systems until the organization is back to a normal, known good state.
Many organizations struggle just to understand what the good state is or if it ever existed, not to mention taking the right actions to return to it. Few organizations are tracking this MTTG systematically.
The Result: Wrong Incentives That Are Burning People and Money
There is a fundamental flaw in this maturity model. It incentivizes SOC analysts to do the wrong thing. Some examples are:
- The best way to improve MTTD is to generate a bunch of alerts “just in case one of them is good”. But this will lead to many false positives.
- The best way to improve MTTR is to close incidents as soon as possible. But this will lead to missing key information for the MTTA and the Post Mortem.
A maturity model based on speeds and feeds will promote the wrong behavior for SOC analysts and will burn people and money.
So, what’s the alternative? It starts with a whole new way of thinking about SOCs — it is about outcomes and measuring end-to-end SOC efficiency. More on that to come in our next blog that focuses on outcomes.
Similar Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence

Action, Remediation, and Lessons Learned: Implementing Incident Response
Recent Posts
What’s New in Exabeam Product Development – March 2024
Take TDIR to a Whole New Level: Achieving Security Operations Excellence

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!