




Many network attack vectors start with a link to a phishing URL. A carefully crafted email containing the malicious link is sent to an unsuspecting employee. Once he or she clicks on or responds to the phishing URL, the cycle of information loss and damage begins. It would then seem highly desirable to nip the problem early by identifying and alerting on these malicious links. In this blog, I’ll share some research notes here on a work in progress and discuss some solution scenarios.
There are many public and commercial data providers that offer blacklisting services or databases for potential phishing domain/URL lookup. However, like any signature-based approaches, newly-crafted phishing URLs cannot be identified this way. Our goal is to flag a suspicious phishing URL previously unknown to blacklist data providers. Machine learning offers a solution used for such a prediction task.
Method
With an abundance of historical phishing domain blacklists, this prediction task is best viewed as a supervised learning problem. Academic work exists in this area in leveraging lexical network and lexical features as basis for learning. Examples of network features are WHOIS, IP address, or geographic properties of the domains. Lexical features are lexical properties of the URL string, such as simple metrics like character length of the URL, number of dots in the domain, directory level count in the URL, and number of URL arguments, similar to the prior work in [1][2], as illustrated in Table 1. For example, given the URL, it has 54 characters (len=54), and the file name has 1 dot (n_dot=1). Lexical features are particularly interesting as these are simple and cheap string operations, requiring no additional data enrichment, unlike the network features. But how much prediction power can get from the lexical features alone in practice? As it turns out, these deceptively simple features do have distinguishing power for normal vs. phishing URLs. The question is how much and how usable they are in practice?
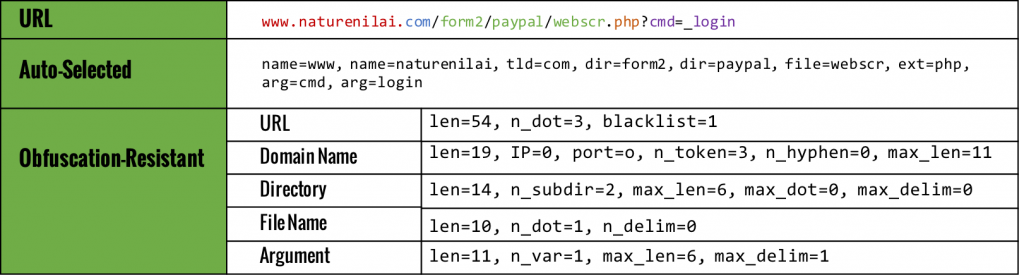
Table 1: Example lexical features
[Source: “PhishDef: URL Names Say It All”, Le, et al., 2010]
We ran experiments. To set them up, PhishTank and OpenPhish provide tens of thousands of positive-labeled URL. Negative-labeled URL are sampled from an enterprise proxy logs, reasonably assuming the majority of traffic is normal. Such a setup is a straightforward classification modeling problem. For the data science audience, two popular machine learning models, Logistic Regression and Random Forest, fit the bill. We found that the best result is achieved by combining the model outputs in an ensemble sense by summing up the respective model scores per URL. The accuracy assessment of prediction scores is always performed on a separate held-out set of positive and negative examples previously unseen by the training set – a standard experiment procedure in typical model training exercise.
Results
ROC plot is used to illustrate the performance of our classifier in the tradeoff of false positive and detected true positive rate. Figure 1 shows our results. Each point on the orange curve corresponds to a potential operating point for a given threshold with which one can expect the corresponding false positive and true positive rate. For example, the red dot in Figure 1 corresponds to an operating point that the model can detect 85% of all true phishing URLs but at the expense of 1% false positive rate. Another convenient metric for evaluating the classifier is the the area-under-the-curve (AUC) in a ROC plot. AUC close to 1.0 means near 100% detection rate with near 0 false positive; the orange curve in the plot would pretty much be a sharp 90-degree curve. In our experiments, we see AUC of 0.9898. Considering we are using nothing other than simple and cheap lexical features, a performance like this is really quite good from general machine learning perspective. However, for practical purpose, can we use this for production in practice? The answer depends on the targeted applications as different applications have different level of tolerance for false positives.
For example, from Figure 1, we can detect 85% of known phishes in an evaluation set with a threshold that corresponds to 1% of false positive rate. This sounds good. However, Exabeam is interested in an operational region with ultra-low false positive rates as in Figure 2, where we only show the false positive rate region less than 0.1%. This translates to just about 10 to 100 daily flagged URLs between small to large environments. Within that operating range, we can see we catch 60% of known phishes in an evaluation set.
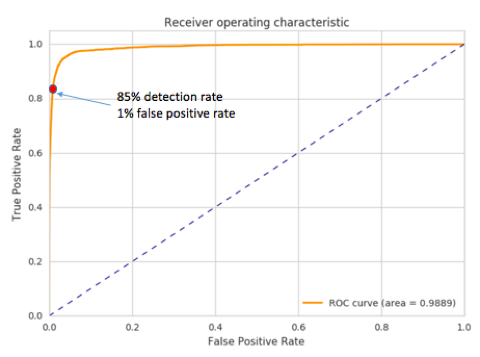
Figure 1: ROC of phishing domain detection
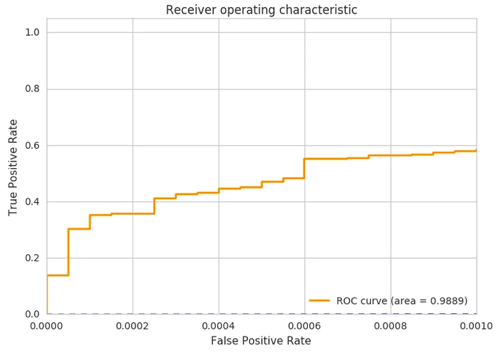
Figure 2: ROC zoomed in for false positive from 0 to 0.1%
Is this good enough? What else can we do to enhance the model performance for production? To make it production ready, additional post-classification filtering steps can be performed to further reduce the false positive rate by leveraging additional contexts.
For example, alert a suspicious URL only if its domain is connected to by a small volume of users or very recent presence in the enterprise log. Or if a high scoring domain is observed to be originated from an email. Removing likely false positives like this allows us to potentially bring in other more interesting alerts, raising the baseline detection rate further in the process. For example, with the simple post-filtering step of excluding alerted URL that are not new in the log, we have found as much as 50% false positive alert reduction is possible to maintain at the same detection rate. Other post filtering steps like this make the phishing URL detection module possible for production.
In this blog, I showed what we can do for the age-old problem of finding phishing URL using just simple lexical features. Beyond academic interest, some interesting accuracy performance figures with real production data are shared with this community. Machine learning methods such as this is part of comprehensive data science-based cyber solutions that Exabeam strives to build.
[1] https://arxiv.org/pdf/1009.2275.pdf
[2] http://www.jatit.org/volumes/Vol88No3/26Vol88No3.pdf
Similar Posts

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?

British Library: Exabeam Insights into Lessons Learned

Beyond the Horizon: Navigating the Evolving Cybersecurity Landscape of 2024
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence
Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!