
-
- Home
>
-
- Blog
>
-
- InfoSec Trends
Sharpening First-Time Access Alerts for Insider Threat Detection
- Apr 22, 2022
- Derek Lin
- 6 minutes to read
Table of Contents
Residents participating in a neighborhood crime watch look out for signs of suspicious activity. A new car parked on the street is probably the first thing to register in a resident’s mind. Other hints like the time of day, what the driver carries, or how they loiter all add up before one decides whether to call the police. A User and Entity Behavior Analytics (UEBA) system works much the same way, with various statistical indicators jointly working together for insider threat detection. Just like seeing a new car on the street in a neighborhood watch, a frequently deployed indicator among UEBA vendors is whether a user accessed a network entity for the first time, be it a machine, a network zone, or an application. Indeed, alerts from this indicator correlate well with malicious insider or compromised account activities. This makes sense, particularly for detection of lateral movement where an adversary is new to the network, accessing multiple entities for the first time.
What is the down side for such alerts? The false positive rate. User behavior is highly dynamic on a network, there will be legitimate user activities triggering such indicators. A high false positive rate will severely reduce the efficacy of this indicator. In this article, I’ll explain how we can use machine learning (ML) to sharpen the precision of this indicator by reducing its false alert rate. For more detail, the research behind this work appeared as a technical paper in the Intelligence Security Informatics Workshop in the November 2017 International Conference of Data Mining.
The intuition is that a user’s first-time access to an entity can be predicted based on how their peers historically access network entities. If the first-time access could have been predicted or expected, then it is not necessary to raise an alert on the user. This reduces the false positives. Continuing with the neighborhood watch analogy, if we could have expected a new car to park on this particular street at this particular hour because neighbors have reported similar recent instances, then a new parked car now won’t register much concern. Similarly, the problem here is to predict a user’s initial access by leveraging information from others’ past access records. Not surprisingly, this is framed as a classical recommender system problem.
A recommender system based approach
If you are not familiar with the recommender system, I will briefly describe it here. In retail analytics, when making a purchase suggestion, the recommender system uses behavioral and contextual data from other users in order to predict a user’s preference for an item. For example, if I and some other users have similar movie watching experiences in the past (behavioral data) or if I and some user group are in the same age bracket (contextual data), I am likely to be recommended a movie which these other viewers have watched but I haven’t. Among the recommender system modeling alternatives, factorization machine is the preferred choice for its ability to incorporate both behavioral and contextual information together. It is beyond the scope of this article to describe the factorization machine algorithm. For a detailed explanation, please refer to this paper from Rendle, et.al.
Knowing what learning algorithm to apply is only part of the work. Like in many machine learning tasks, suitable data conditioning work is required prior to its use as input for learning. Below are highlighted at least two issues to address.
Recommender system learning issues to address
First, user-to-entity access on a network is very sparse. Typical users only access a handful of entities. It is well known that data sparseness poses difficulty to a recommender system. To reduce the data sparseness, users who accessed very few entities, as well as entities which were accessed by very few users, are simply removed from learning. We do not have enough historical behavioral information to learn from them. This means that for such users, we simply let their first-access alerts stand. Only users for whom we have enough information are evaluated for potential alert suppression on their activities.
Second, the recommender system learning is a process of gaining information from the past user-to-entity access and non-access records in history. However, in cases where users have no access records to entities, that does not mean our recommender system should blindly learn from that. A user and an entity without an access connection is due to:
- The user having no access privilege due to security policy
- The access being allowed, but they have not accessed yet (but may in the future; these are the accesses which we want to predict)
Since this is a supervised learning method, each sample for learning, e.g., a user-to-entity tuple, must be labeled as “have access” or “not have access”. Tuples are assigned with observed access as “have access”; however, all other tuples can’t be blindly assigned as “not have access”. Doing so would leave no room for any future prediction, as all possible user-to-entity access are now all accounted for in the history. To allow meaningful learning and prediction, this issue is successfully addressed by carefully sampling some tuples and only then assigning them with the “not have access” label for learning, leaving all the other tuples available for future prediction. Please refer to our paper for detail.
Before I reveal the results, it is interesting to see the effect of using different types of contextual data for the factorization machine-based recommender system modeling. Contextual data, such as peer groups, helps the model to predict whether a user’s access to an entity is expected if some of their peers have already accessed the entity at some point in time. The results of our experiments showed that the peer data defined as the combination of the user’s Windows security group (e.g., “memberOf” key in Windows LDAP data) and the department information helped the model yield the best prediction error, compared to the alternative where there was no contextual data leveraged or where only the Windows security group was used.
Evaluation data
Now let’s see how the method performs to suppress the false positives from raised alerts. We’ll look at the first-time access alerts on users accessing four different types of network entities:
- NKL: machines accessed by users via NTLM or Kerberos authentication protocol
- RA: machines remotely accessed by users for file share or printer connection
- NZ: network zones accessed by users
- EP: endpoint processes run by users
The method makes a classification decision whether an alert should be kept or otherwise suppressed. To quantitatively evaluate this classifier, we need alerts pre-labeled as legitimate or as malicious. Yet, known and validated malicious insider threat activity on an enterprise is either non-existent or hard to obtain, while nearly all network activity at any given time is legitimate.
Evaluation setup
To allow an evaluation, we assume all observed alerts from logged data are of legitimate user behavior; these are negative-labeled samples. This assumption is generally valid, as nearly all such alerts from any given data period are typically due to the dynamic nature of user behavior on a network. Ideally, if the recommender system works as intended, the prediction scores for these are close to the number one. (Closer to one means that the access is expected, while closer to zero means that the access is not expected.)
Positive-labeled samples are synthesized to mimic malicious behavior reflecting scenarios in which either a masquerading attacker does not know his way around the network, or an ill-intentioned insider connects to network entities inconsistent to a victim’s and their peers’ habitual patterns. The synthesis is performed via the negative sampling technique by pairing a randomly, but carefully selected, entity to a user as if the user just had a first-time access. An example selection criterion is that the selected entity to pair with a user is one that has not been accessed by the user themself or by their peers in the past. Ideally, if the recommender system works as intended, the prediction scores for these are close to zero – the access is not expected.
Results
Figure 1 shows the ROC curves of the classifier performance on alerts raised on users accessing the four entity types. An ROC curve shows the tradeoff in the detection rate on the positive-labeled alerts vs. the false positive rate (or the alert suppression rate) on the negative-labeled alerts. As we can see, for alerts over the RA, NZ, and NKL entity types, we can get close to 50% of alert suppression rate while maintaining near 100% detection rate. This is very good. The performance for the EP alert type is still good, but is somewhat inferior to others, having approximately a 90% detection rate combined with a 50% suppression rate. This is perhaps explained by the fact that in real-world situations, endpoint processes exist that are run by many users — normal users and attackers alike. The recommender system errs on the side of expecting such processes to be run by users too frequently, inadvertently suppressing more alerts than desired, including those from synthesized malicious access.
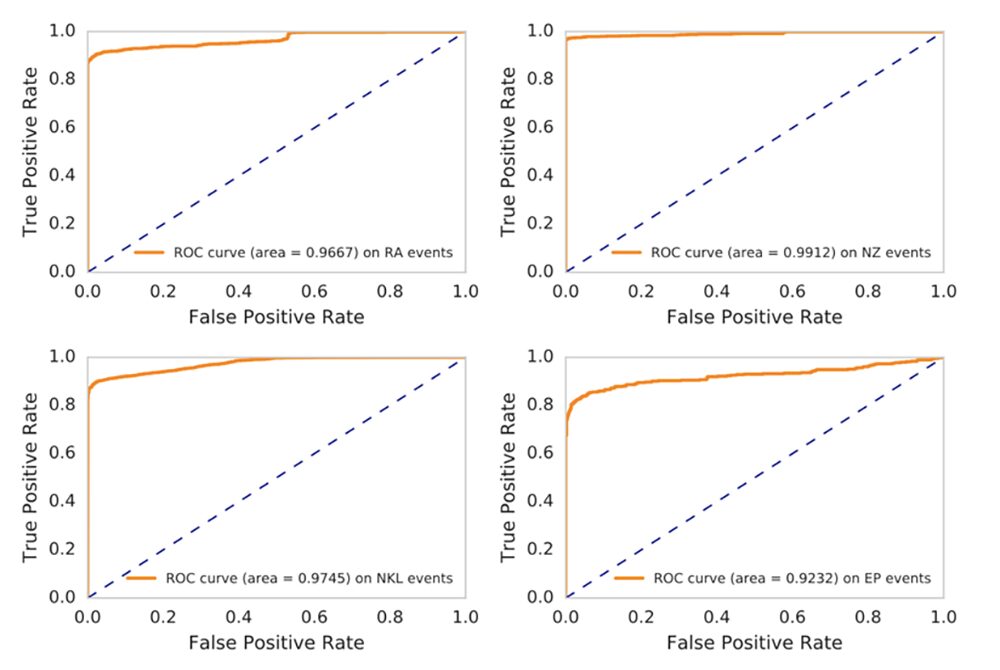
To summarize, the user-to-entity first-access indicators for alerting are popularly deployed in UEBA systems for their ease of interpretation and good correlation with malicious activities. I showed a factorization machine-based recommender system method to reduce false positives from these alerts. Contextual data from peer groups are considered in learning. I pointed out some issues that must be addressed before applying the learning. With real world data, alerts from users accessing four different entity types are evaluated. The method is shown capable of reducing false positive alerts of the first-access indicator while maintaining its detection rate.
Work such as this is important for UEBA. All statistical indicators have varying degrees of false positives. When an effort is made to improve the precision rate for each indicator, the overall anomaly cases presented to analysts will have good precision, reducing the false positive fatigue.

Derek Lin
Chief Data Scientist | Exabeam | Derek Lin is the Chief Data Scientist at Exabeam, building products to help security teams accelerate and improve threat detection, investigation and response (TDIR) by adding intelligence to their existing security tools. His current and prior machine-learning research interests include behavior-based security analytics, risk-based banking fraud detection, and speech and language recognition. He holds numerous patents and authors papers in areas of fraud detection and cybersecurity.
More posts by Derek LinLearn More About Exabeam
Learn about the Exabeam platform and expand your knowledge of information security with our collection of white papers, podcasts, webinars, and more.
-
 Blog
Blog
LogRhythm SIEM July 2026 Release: Accelerating Investigations and Expanding Visibility
- Show More
