





Security analysts often wrestle with the high volume of alerts generated from security systems and much like the protagonist in The Boy Who Cried Wolf, many alerts tend to be ignored. Human analysts quickly learn to ignore repeated alerts in order to focus on the interesting ones. Learning to screen out repeated alerts as false positives allows analysts to focus their finite time where it matters most. A natural question, then, is whether we can train a security system to do just the same. In this blog, I show how we can provide a learning curve to a User-Entity Behavior Analytics (UEBA) system so that only the most interesting information surfaces up to the analysts.
A typical UEBA system consists of a collection of factual, statistical, and machine-learning based indicators. The number of these indicators ranges from the tens to hundreds depending on available data sources. Indicators trigger alerts independently. The most practical method for organizing and prioritizing these alerts is to group them in a user’s or an entity’s time activity window, a.k.a. a session (with a fixed or variable time duration). Within this session, we sum up their score contributions and present the score-ranked sessions to analysts for prioritization.
A Scoring Problem
Not all of the indicators are born equal in their potential to raise an alert. An indicator such as a user’s first-time access to an asset, although often associated with a credential misuse attack, tends to trigger often across the user population simply due to the very dynamic nature of enterprise networks: new machines are added regularly, users’ functional roles change, etc. On the other hand, another indicator, designed to detect a pass-the-hash attack is expected to trigger rarely since incidents of this nature do not happen frequently. While we definitely want to keep the strong indicators that trigger rarely, we can’t afford to ignore the weaker indicators that trigger often. All indicators are manually crafted and are information-bearing to varying degrees. In behavior analytics, a collection of independently-triggered weak indicators can still serve up a strong signal. Yet, if all alerts are regarded equal in their score contributions, then top score-ranked sessions presented to analysts are likely to be flooded with false positive alerts, a case of crying wolf, rendering the security system less useful.
We desire a scoring system that maintains the score contribution from rarely-triggered indicators while reducing that from often-triggered indicators. In other words, we want to identify a weight for each indicator so we can weigh each indicator’s score contribution accordingly.
I now introduce a simple yet practical Bayes statistics-based method to solve this problem.
Bayes Method
The key insight is to regard an indicator’s weight as the probability of seeing an attack or malice, M, in the event that this indicator is triggered, x; or P(M|x). Consider this weight as the attack risk in observing the triggering event of an indicator. This quantity, in Bayes statistics, is simply
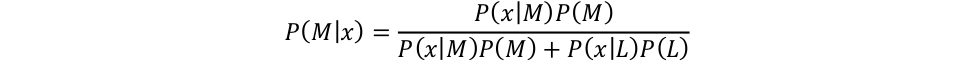
where L is non-attack or legitimacy. To compute the risk P(M|x), we need to resolve all the terms on the right-hand side. Each of the terms can either be computed directly from data, or be estimated with quantities reflecting domain expert’s opinion, as how Bayes framework is used. Once P(M|x) is computed, we use it to weigh the score contribution of the indicator. As a result, the risk of a frequently-triggered indicator is close to zero; the risk of a rarely-triggered indicator is close to one.
I just described a way to weigh indicators using Bayes statistics. Each indicator has a global risk as it is computed based on the population data; this risk value is the same for all users or entities in an environment. In Exabeam’s patent-pending work, we extend the above to weigh indicators on a per-user basis. An indicator now has local or per-user risk, dynamically set depending on user context. If we have an indicator that doesn’t trigger often across the population, but triggers frequently for a particular user, the per-user risk is adjusted lower from the static global risk accordingly. Similarly, if an indicator triggers often across the population, but rarely triggers for this user, the weight is also adjusted accordingly. Furthermore, in addition to the notions of global and per-user risks per indicator, the framework permits context-dependent risk per indicator as well. An indicator can get a different weight depending on the context in which it is triggered. An example indicator is a 3rd party provided malware alert, with contexts defined as which security vendor provided the alert. This is interesting, as not all security vendors have the same level of precision in their alerts. Details of this Bayes framework, experiment data, and results of its false positive reduction efficacy are best left for a future blog.
This method learns from historical data to determine how best to calibrate the score contribution of a security indicator’s alert. In summing up the weighted contributions from security alerts, false positives of top scored-ranked sessions are reduced, allowing more interesting sessions to surface up in ranks – exactly what security analysts desire in a security system.
Similar Posts

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?

British Library: Exabeam Insights into Lessons Learned

Beyond the Horizon: Navigating the Evolving Cybersecurity Landscape of 2024
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence
Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!