




How Asset Clustering Provides Improved Alert Quality – A Machine Learning Application

For detection-based anomaly alerts, their supporting context is paramount. Without it, no alert is actionable and—at best—only contributes to the analyst burden of dealing with false positives.
For example, a commonly deployed alert monitors when a user has accessed an asset for the first time. But such an alert isn’t significant unless it’s fortified with contextual data, such as the user type (privileged vs. non-privledged) and the nature of the asset (critical vs. non-critical).
I’ve long advocated for the use of data-driven methods to gather contextual intelligence whenever it’s unavailable or is suboptimal. Deriving such security intelligence is a prime machine learning application. In this post, you’ll learn about a machine learning use case that clusters network assets (or devices) into groups to improve alert quality from peer-based analysis.
The unique challenge of performing peer analysis for assets
Peer-based analysis calibrates the risk of a user or network entity’s anomaly alert by comparing its behavior with that of a peer. For example, user Alice is tagged with peer group labels of Engineering, Support, and Pre-Sales within Active Directory (AD). Each group is a collection of users, Alice being one.
The risk level associated with Alice initially accessing an asset depends on whether it’s also the first access for her peer group. Discussed previously in this post, dynamically finding the best peer group (or groups) that best represent Alice from a behaviorial standpoint is a machine learning use case. This works well for user-centric peer analysis, where peer grouping data is available in Active Directory.
But the peer grouping of data for assets isn’t typically maintained; it’s not critical from an IT operations perspective. Does this prevent us from performing peer analysis for assets—the E in UEBA (User Entity and Behavior Analytics)? Despite the challenge of not having asset group data, the answer is no. In our recent work, we’ve shown how to cluster network assets in peer groups that are behaviorally similar. By leveraging data from a user-to-asset connectivity log, we can develop asset peer groups—a piece of contextual information that enables us to perform asset-centric peer analysis.
Let’s sketch out this core idea.
Deriving asset peer groups—looking for the “behaviorly similar”
The method of collaborative filtering in machine learning has found wide applications. This is particularly true in the retail industry where, based on shoppers’ buying records, “similar” items are grouped together for a purchasing recommendation. We’ve adopted this same idea by leveraging user-to-asset logon data to group assets that are behaviorally similar from a historical perspective.
“Behaviorially similar” pertains to those assets repeatedly accessed by a given set of users deemed as a peer group. But how do we actually perform the clustering? In data science, there are many approaches. Which machine learning method to use depends on use case characteristics and requirements.
For our particular use case, the considerations are:
– An asset is expected to have membership in one or more derived groups.
This is similar to the Active Directory’s user peer groups, where a user can belong to multiple user peer groups. (For example, Alice belongs to both Engineering and Pre-Sales departments, each having different weights).
– The derived asset peer groups must be interpretable.
Output intepretability is always a critical requirement in security analytics work.
– The number of derived groups is not known beforehand.
A proper metric must be designed to evaluate for the optimal number of groups.
– The asset clustering algorithm must provide stable output.
Some algorithm classes are stochastic in nature, meaning their outputs have a degree of randomness and are non-repeatable under identical input. This isn’t acceptable for operational use, such as in the case of re-running the system.
For data scientists, the above considerations are addressed by using non-negative matrix factorization (NMF) on user-to-asset access logs, while incorporating and leveraging a user’s Active Directory user peer labels to provide interpretable meanings to output asset clusters. Being beyond the scope of this post, the citation provides a full description.
The net outcome is that an asset can belong to one or multiple clusters, each having different weights or degrees of membership.
Table 1 below shows sample output asset clusters from an enterprise environment consisting of 3,500 devices. An asset can belong to one or more clusters, and can have varying degrees of membership. Each cluster is semantically interpretable.
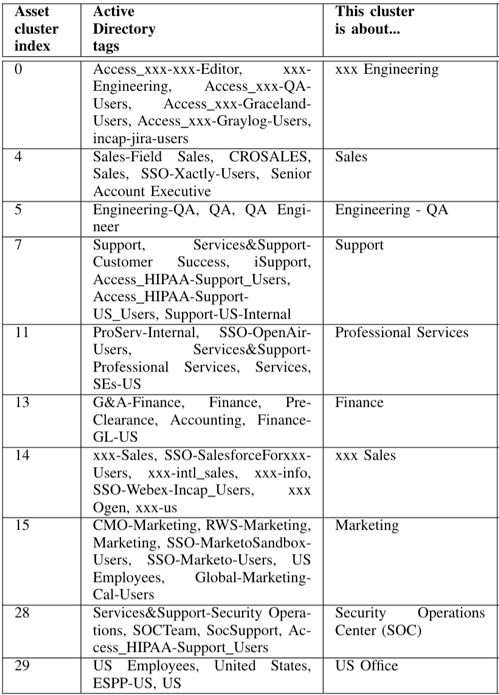
Table 1: A readout of sample output asset clusters from an enterprise environment consisting of 3,500 devices.
For example, cluster ID 13 in the left column is an asset group described by the center column tags, G&A-Finance, Pre-Clearance, Accounting, in addition to those in the right column. (They’re the user peer group labels from the Active Directory data for those users that collectively have dominant activities on the assets.)
From the descriptive labels, one can infer that this cluster is about assets related to finance activities—or “Finance” as annotated by the domain expert. In short, not only are assets clustered into groups, but the groups have tags (or labels) that are interpretable, with weights that can be displayed in a word cloud.
Applying context intelligence for accurate security analytics
Providing the needed context for asset analysis, Exabeam uses peer-based analysis extensively for risk scoring. But how does this compare to other, more simple schemes of determining asset peer groups and labels?
What about simply set a peer label to the one ‘best’ AD user group label for the single user having the most dominant activites related to a given asset? For example, could a laptop Alice uses most frequently belong to an asset group labeled “Engineering,” if that’s a good AD user peer label for her?
This approach makes a fixed decision in assigning an asset to a single cluster. It doesn’t allow for the flexibility of the asset to belong to multiple clusters afforded by our research. A server can indeed belong to multiple peer groups; for example, it may be characterized by user access activities from both Engineering and Support. To aid accurate peer analysis, this lack of flexibility has been shown experimentally to be suboptimal in its detection capacity.
Summary
To be able to assess complete security analytics, using machine methods to develop contextual intelligence from data is essential. The better we understand the nature of network entities, whether they be users or assets, the higher performing a threat detection system will be. For the purpose of asset peer analysis, herein we’ve described how Exabeam uses user-to-asset activity data to produce interpretable asset peer groups.
To help protect your organization and reduce risk, learn more about Exabeam Advanced Analytics and how it automatically detects behaviors that are indicative of a threat.
“Generating Interpretable Network Asset Clusters For Security Analytics,” Anying Li, Derek Lin, IEEE BigData 2018 Conference, BDA4CID workshop, December 10, 2018.
Similar Posts

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?

British Library: Exabeam Insights into Lessons Learned

Beyond the Horizon: Navigating the Evolving Cybersecurity Landscape of 2024
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence
Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!