




In user and entity behavior analytics (UEBA), a security alert is best viewed in context as discussed in my past webinar. A user’s peer groups provide useful context to identify and calibrate that user’s alerts. If a user does something unusual on the network, such as logging on to a server or accessing an application for the first time, we may reduce or amplify the risk score of this activity depending on whether the peers of this user (a member of his peer group) typically do the same or not. This is sound. However, what constitutes a user’s peer group and how do we design a peer-based scoring framework? In this blog, I address these practical questions from a data science perspective.
Single Peer
A typical data source for finding a user’s peers is Active Directory (AD). Enterprises maintain in AD properties such as each user’s department, division, title, and manager, etc. Each one is a candidate for peer group analysis. Choosing just one of these for peer analysis would be a first simple approach. For example, if a user accesses an asset for the first time and none of his peers in the same department group have been known to do the same, it would be a reason to increase the risk score for the user.
However, in practice, there are at least two issues with this simple approach. First, these user properties are static and not always up to date. Missing peer information for a user, such as which department a user belongs to, is common. Also, as the user changes role or moves to a different project, the fields in Active Directory are not kept up to date. We observed that typical coverage for each of these individual AD’s user properties on a population can range from 50% to 90%. This means that users without a peer label don’t participate in peer analysis, resulting in blind spots in risk assessment. Second and more important, conducting peer analysis on a single dimension for a user does not translate well in real-world environments. In most cases, a user does belong to multiple peer groups. For example, a user be part of the “R&D” peer group, “Chicago” location, a source control “github” administrator, and an executive member at the same time. Instead of evaluating the user’s activities using only one peer context, a user’s out-of-norm behavior may be viewed within all four peer contexts.
Multiple Peers
One way to deal with the above is to allow multiple peer groups per user for peer analysis. By combining all relevant user groups, we minimize blind spots in risk assessment and comprehensively measure the risk of the user. The same holds true not only for the user, but also for any entity. This leads to the following analytic issues:
- Multiple peer groups can potentially give conflicting information. For example, a user’s action can be normal for two of his peer groups – a department-based peer group of “Engineering” and a title-based peer group of “Support Engineer” – but abnormal for the location-based peer group of “US-West”. How do we account for conflicting results from different peer groups? Additionally, should all peer groups be given the same weight in anomaly detection and risk calculation?
- Some users have more peer groups than others. A user with one peer group may be scrutinized less than another with three peer groups. Risk attention is not equal for users that have different number of peer groups.
- Peer group sizes are different. Small peer groups are expected to trigger alerts more often than large peer groups as the former’s behavior typically can be explained away when it is placed in a larger group’s context. It would be desirable to take peer sizes into account.
Fairly complicated, it seems. What to do? At Exabeam, we developed a solution for multi-peer analysis that is dynamic in nature.
Per-user degree of membership to peer
We recognize that while a user may belong to multiple peer groups, she would have different degrees of membership (how close is she to the other members of the group behavior-wise) to each of these peers. The degrees of membership to a peer group can also be expected to vary over time. She may simultaneously be assigned two peer groups “Engineering” and “PreSales”. In the past, she might have been more strongly associated with Engineering, but now with PreSales as her job scope changes. This degree of membership is crucial for peer analysis for calibrating user’s anomalies. We use the concept to dynamically assess multiple peer signals by weighting according to degrees of membership.
To compute a user i’s degree of membership to a peer group P_k, we leverage behavior data over a historical period. Let d_ij be the calculated distance between user i and user j based on their historical behavior data, for example, a divergence metric over access frequency distribution of accessed assets. Then, the user i’s degree of membership to peer group P_k, DM_ik, is a function over all pair-wise distances between user i and all peers j in P_k; an example may be a simple average function or another more sophisticated choice. See figure below for illustration.
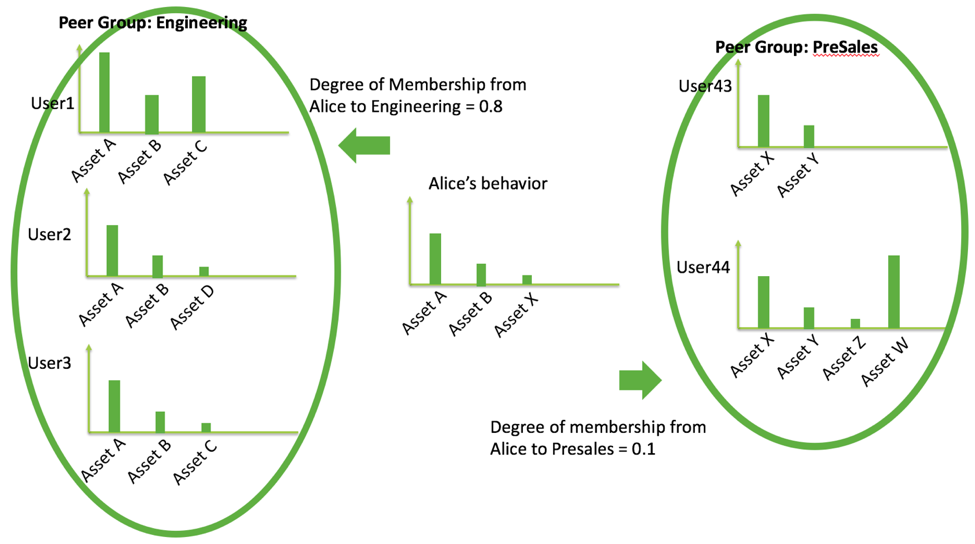
To summarize, a single-peer analysis is insufficient for proper anomaly detection. While multiple-peer analysis is a sound concept, it needs to take into account for the dynamic nature of enterprise environments and work for a broad set of entities in the environment. At Exabeam, we use behaviors to determine the possible peer groups for an entity. The per-user degree of membership allows us to calibrate or weigh the importance for each multiple peer alert based on observed historical behavior. Each user maintains her own degree of membership to various peer groups, for maximal peer analysis accuracy.
By developing a metric of using historical data to measure distance between two users, one can also derive a notion of “cohesiveness” for a given peer group that measures the similarity of behaviors of the members in that group. A threshold can be applied to retain only peer groups with reasonable cohesion for the purpose of peer analysis.
Behavior-based peer analysis can extend from here. Instead of relying on Active Directory to provide the peer information, we can use the same behavior data to automatically derive new peer groups. This is particularly useful to discover groups unknown to Active Directory, for example, by clustering users based on behaviors over SaaS applications or physical building access. This is perhaps a topic for a future blog.
Similar Posts

NIS2 Expands Its Scope for EU Entities

Aligning With DORA for Financial Entities in the EU

Introducing Threat Detection, Investigation, and Response (TDIR) for Public Cloud
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!