




Looking for outliers or something different from the baseline is a typical detection strategy in user and entity behavior analytics (UEBA). One example is a user’s first-time access to an asset such as a server, a device or an application. The logic is sound and is often used as an example in the press for behavior-based analytics. However, it is an open secret among the analytics practitioners that alerts of this type has a high volume of false positives. Even though a first-time access alert has good correlation with malicious behavior, legitimate user behavior on network is too dynamic for it to be useful on its own. For example, the user may be accessing a new application as he moves to a different project. Or he may be accessing a new database server that replaced the old server. In this blog, I’ll describe how we can use machine learning to enhance the detection signal from first time abnormal behaviors.
As with other detection mechanisms, context is king. Many security vendors these days generically talk about “peer analysis” as one mechanism that provides valuable context. Yes, it is a must-have analysis for a UBA solution. But how does it work in practice? At Exabeam, we take a two-pronged approach that is based on data science.
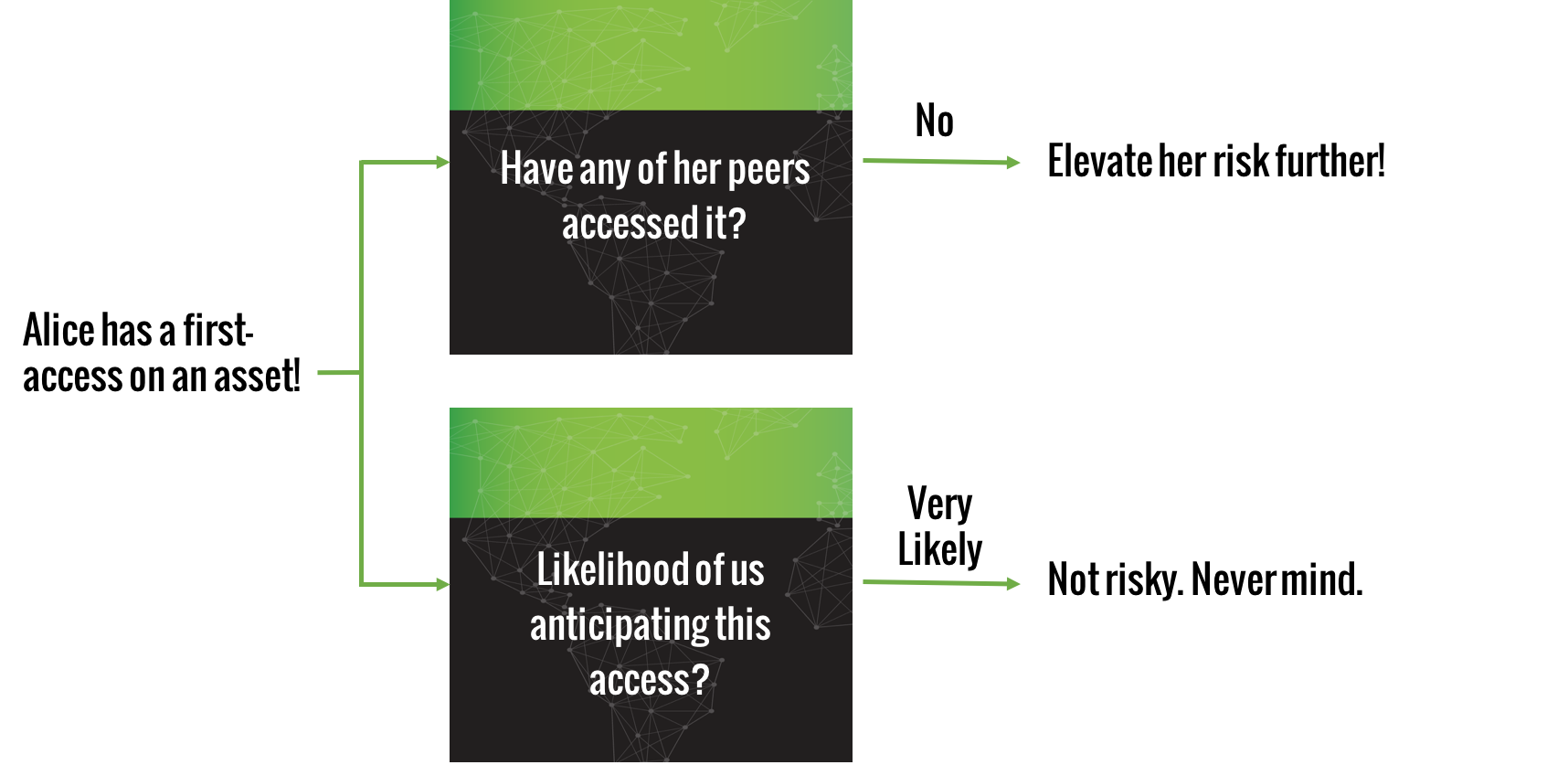
Figure 1.
When Alice triggers a first-access anomaly on an asset, the first path in Figure 1 determines if we should further elevate the risk by checking whether any of her peers has touched the asset in the past. If none of her peers has done so, then her first-access anomaly becomes more significant. In practice, one challenge is to determine who the most representative peers for Alice are. Standard Active Directory (AD) data gives us all defined peer group types (departments, geolocations, titles) while members within and across types can overlap. Alice can simultaneously belong to one or more peer groups; some are more relevant or useful than others. I had described a novel data science application in an earlier blog to dynamically determine a given user’s best peer groups before performing the peer analysis. This is peer analysis in the first order.
But the story doesn’t end here. In addition to the described peer analysis for risk elevation, can we have a complementary method to decrease the risk on Alice’s first-access anomaly? In other words, can we reduce the chance of false positives? We want to use information from historical behaviors across all users in the population to see if we could have anticipated Alice’s first-access, as in the second path in Figure 1. If her access could have been anticipated or predicted, then the raised first-access alert becomes less significant; it can even be thrown away entirely as a false positive alert or a very-low-risk anomaly.
Such prediction requires a machine learning solution. At Exabeam, our patent-pending solution is built on the concept of collaborative filtering. Collaborative filtering is leveraged by retail or ad marketers to recommend users on items to buy or to view. Here is a simple illustration for movie recommendation: We observe a person A tends to give similar ratings to a number of movies that some persons, B, C, and D, also rated. For a new movie A hasn’t watched, we can make a reasonable prediction on how A would have rated this movie based on B, C and D’s past known rating and make a movie recommendation, or not, accordingly. Collaborative filtering allows us to do this at a large scale.
This idea applies to our user-to-asset access “recommendation” or prediction problem. Applying the same idea here, the asset is equivalent to a movie and the user’s movie rating is equivalent to the user’s asset access count. If Alice’s first-time-accessed asset could have been predicted with some access frequency, then the access is less of a surprise and therefore less risky. A large predicted frequency means the raised first-time access alert is not risky at all.
Moreover, by looking at historical data, we know which user accessed what asset with certain frequency. Every user is represented by a large vector whose size is the number of assets on the network; for example, 10K users and 40K assets in a medium sized enterprise environment. Now structure this data in a matrix form of 10K rows by 40k columns where an entry (i,j) stores the access frequency count for i’th user and j’th asset. As you can imagine, most entries are zero. This is a sparse and a high dimensional data used as input to our recommender system. A popular algorithm choice to implement the recommender system has been Matrix Factorization which aims to reduce the original space to a lower dimensional space. Another is Factorization Machines [1].
If you are new to factorization machine, its model equation follows. x is a feature vector of n elements indexed by i and y is the target vector. For a factorization machine with degree d=2,
![]()
![]() are the model parameters to be estimated.
are the model parameters to be estimated.
![]()
is the dot product of two vectors size k which is a hyperparameter defining the latent dimension of the factorization. It is this term that captures the important hidden pairwise interactions between variables in factorization machine.
How well does it work in practice for false positive reduction for user’s first access to an asset? At Exabeam, we have seen as much as 30%-50% reduction in alert suppression in various scenarios in real environments. This is a great example of machine learning at work for UEBA where machine learning is not only used to enhance detection but also to minimize false positives.
[1] Rendle, Steffen. Factorization Machines.
Similar Posts

Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?

British Library: Exabeam Insights into Lessons Learned

Beyond the Horizon: Navigating the Evolving Cybersecurity Landscape of 2024
Recent Posts

What’s New in Exabeam Product Development – March 2024

Take TDIR to a Whole New Level: Achieving Security Operations Excellence
Generative AI is Reshaping Cybersecurity. Is Your Organization Prepared?
Stay Informed
Subscribe today and we'll send our latest blog posts right to your inbox, so you can stay ahead of the cybercriminals and defend your organization.
See a world-class SIEM solution in action
Most reported breaches involved lost or stolen credentials. How can you keep pace?
Exabeam delivers SOC teams industry-leading analytics, patented anomaly detection, and Smart Timelines to help teams pinpoint the actions that lead to exploits.
Whether you need a SIEM replacement, a legacy SIEM modernization with XDR, Exabeam offers advanced, modular, and cloud-delivered TDIR.
Get a demo today!